the level of granularity at which the program is encoded and decoded (function-level, basic block-level, instruction-level, or byte-level), and
This transformation is similar to the Jit transformation, except the jitted code is continuously modified and updated at runtime.
Our implementation is a generalization of a number of previously published schemes:
Each of these schemes can be seen as a combination of two properties:
the level of granularity at which the program is encoded and decoded (function-level, basic block-level, instruction-level, or byte-level), and
the codec that determines how a function/block/etc. should be encoded and decoded.
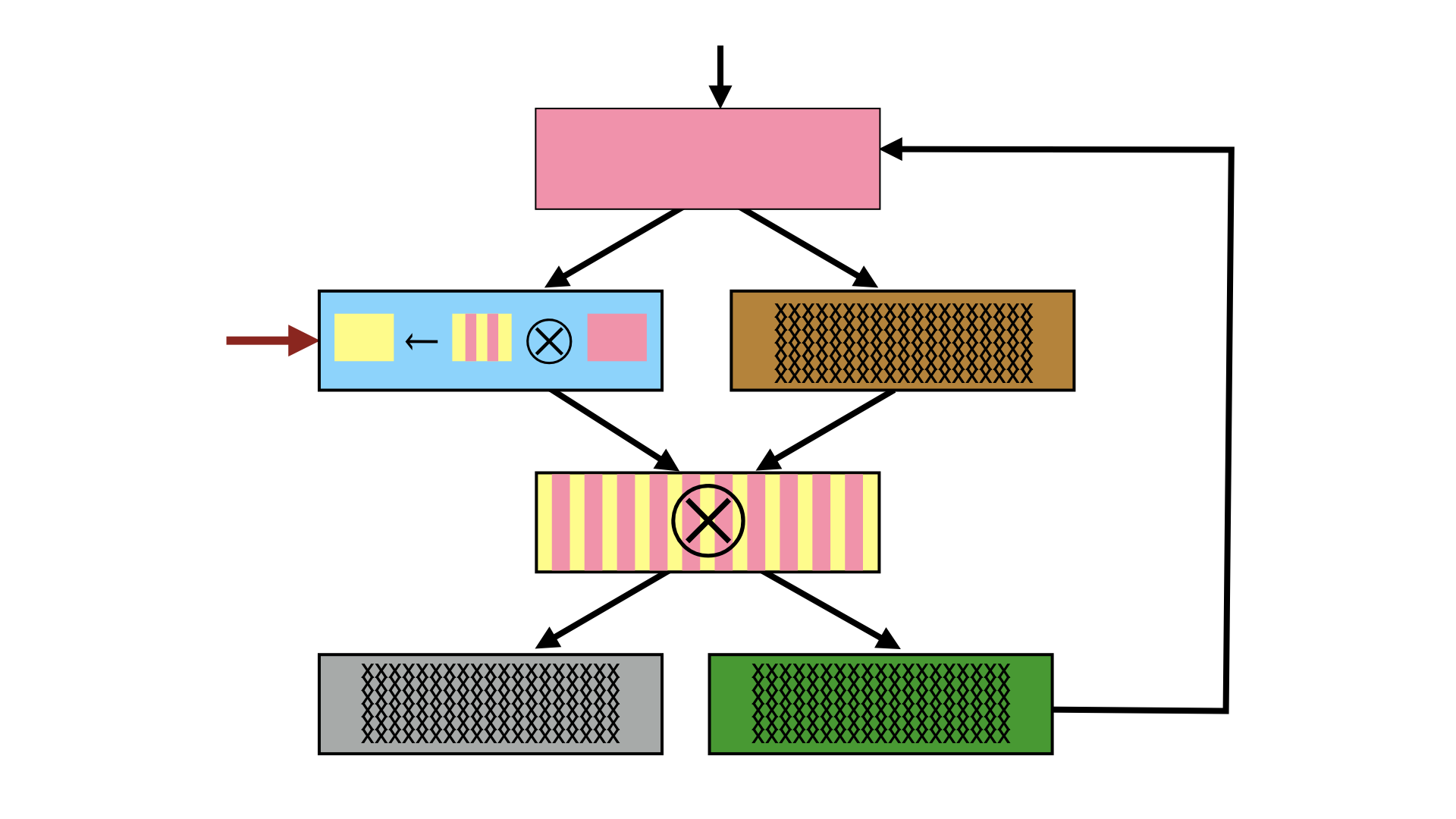
For example, Aucsmith's scheme works on basic blocks and encodes two blocks by xor:ing them with each other.
Pink-and-yellow striped block is the XOR of the pink and the yellow blocks. Right before we want to execute the yellow block, the blue block XORs the striped block with the pink block, and the yellow block appears in cleartext and we can jump to it.
Cappaert's scheme was originally designed to work at the granularity of functions and encodes by encrypting using a standard encryption algorithm, such as AES:
To avoid having to embed keys directly in the executable where they are easy to find, this scheme uses other blocks as the key. Here, the yellow block is encrypted using the pink block as the key. Before we execute the yellow block, the blue block decrypts it. Then the yellow block appears in cleartext, and we can jump to it.
Kanzaki's scheme works at the granularity of the raw bytes of the program and encodes/decodes by patching holes left in the code:
Here, the blue block has a hole in it which the pink block patches. Then control can continue with the blue block, after which the yellow block will re-insert the hole.
Madou's scheme was originally designed to work at the function level and encodes by letting blocks occupy the same space at runtime. A special PATCH function restores blocks before they are needed:
Here, the yellow and grey blocks both exist in the same memory location. The blue block decodes the yellow block by patching it; then jumps to it, then the brown block needs to execute the gray block, so it patches it, and then jumps to it.
Our implementation of these schemes works at the granularity of basic blocks and can be instantiated with arbitrary codecs (encoding/decoding schemes):
intially, before a function starts executing, (a subset of) its basic blocks are encoded using one of the available codecs,
prior to a block being executed it is decoded, and
after a block has finished executing it is eventually re-encoded.
Note that in our implementation multiple encoding schemes can be used within one function: some basic blocks may be encoded using Aucsmith's scheme, some with Cappaert's scheme, etc.
We will add new codecs over time. Currently, the following are implemented:
none: No encoding
ident: No encoding
ident_loop:
The identity encoding using a copy loop of primitive JIT instructions.
xor_transfer: An xor encoding using a single xor JIT instruction.
xor_byte/word/qword_loop:
An xor encoding using a copy loop of byte/word/qwoard-size primitive JIT instructions.
xor_call:
Another xor encoding, but this one is outlined, calling a function which iterates over the
encoded block.
xtea:
Encrypts/decrypts a block using the xtea cipher.
stolen_byte/short/word:
Encodes/decodes by filling in/leaving a hole in the basic block.
| Option | Arguments | Description |
|---|---|---|
| --Transform | JitDynamic | Turn a function into a sequence of instructions that dynamically builds up the function at runtime, and continuously modifies them. |
| --JitDynamicEncoding | hard, soft | How the jitted instructions are encoded. Default=hard.
|
| --JitDynamicFrequency | INTSPEC | How often to jit the code at runtime. 0=only the first time; n>0=Every n:th time the function is called. Default=0. |
| --JitDynamicOptimizeBinary | INTSPEC | Optimize the jitted binary code. 1=omit frame pointer, 2=omit unused assignments, 4=merge ADDs and MULs. Default=1|4=5. |
| --JitDynamicImplicitFlowHandle | BOOLSPEC | Insert implicit flow to the generated function handle. Default=false. |
| --JitDynamicImplicitFlow | S-Expression | The type of implicit flow to insert. See --AntiTaintAnalysisImplicitFlow for a description. Default=none. |
| --JitDynamicObfuscateHandle | BOOLSPEC | Add an opaque predicate to the generated function handle. Default=false. |
| --JitDynamicObfuscateArguments | BOOLSPEC | Add bogus arguments and opaque predicates to the jit_add_op function calls. Default=false. |
| --JitDynamicDumpOpcodes | INTSPEC | Print the jitter's bytecode. OR the numeric arguments together, or 0 for no dumping. Default=0.
|
| --JitDynamicTrace | INTSPEC | Insert runtime tracing of instructions. Set to 1 to turn it on. Default=0. |
| --JitDynamicTraceExec | BOOLSPEC | Annotate each instruction, showing from where it was generated, and the results of execution. Default=false. |
| --JitDynamicDumpTree | BOOLSPEC | Print the tree representation of the function, prior to generating the jitting code. Default=false. |
| --JitDynamicAnnotateTree | BOOLSPEC | Annotate the generated code with the corresponding intermediate tree code instructions. Default=false. |
| --JitDynamicDumpIntermediate | BOOLSPEC | Print the generated intermediate code at translation time. Default=false. |
| --JitDynamicCodecs | none, ident, ident_loop, xor_transfer, xor_byte_loop, xor_word_loop, xor_qword_loop, xor_call, xor_call_trace, xtea, xtea_trace, stolen_byte, stolen_short, stolen_word | How blocks should be encoded/decoded. Default=*.
|
| --JitDynamicKeyTypes | data, code | Where the encoding/decoding key is stored (for xor and xtea encodings) Default=data.
|
| --JitDynamicBlockFraction | FRACSPEC | Fraction of the basic blocks in a function to encode Default=all. |
| --JitDynamicRandomizeBlocks | BOOLSPEC | Randomize the order of basic blocks Default=true. |
| --JitDynamicReEncode | BOOLSPEC | If true, blocks will be re-encoded after being executed. If false, blocks will be decoded once, and stay in cleartext. ('False' is not implemented; this option is always set to 'true'.) Default=true. |
| --JitDynamicOptimize | BOOLSPEC | Clean up the generated code by removing jumps-to-jumps. Default=true. |
| --JitDynamicDumpCFG | BOOLSPEC | Print the jitter's Control Flow Graph. This requires graphviz to be installed (the dot command is used). A number of pdf files get generated that shows the CFG at various stages of processing: CFGAfterInsertingAnnotations.pdf, CFGAfterSimplifyingJumps.pdf, CFGAfterTranslatingAnnotations.pdf, CFGBeforeInsertingAnnotations.pdf, CFGDumpingFunctionFinal.pdf, CFGDumpingFunctionInitial.pdf, CFGFixupIndirecJumps.pdf, CFGReplaceWithCompiledBlock.pdf, CFGSplitOutBranches.pdf, CFGSplitOutDataReferences.pdf, OriginalCFG.pdf Default=false. |
| --JitDynamicTraceBlock | STRING | Print out a message before each block is executed. (Not currently implemented.) Default="". |
| --JitDynamicCompileCommand | STRING | A string of the form "gcc -std=c99 -o %o %i", where "%i" will be replaced with the name of the input file and "%o" with the name of the output file. For example, if your program uses the math library, you should set --JitDynamicCompileCommand="gcc -std=c99 -o %o %i -lm". Default="gcc -std=c99 -o %o %i". |
The Dynamic transformation follows the following steps to transform a function F:
Convert F to jitted code, identically to the
Jit
transformation;
Construct a CFG from the jitted code;
Transform the CFG, making certain instructions into their own blocks which
will not be encoded:
make every branch instruction a separate basic block;
make every instruction that references in-code data blocks a separate basic block;
add a level of indirection for indirect branches.
1
2
3
Add any necessary cipher functions to the executable;
Decide, for every basic block, which codec it should use (if any);
For each basic block that should be encoded, find allowable points within the CFG where decoders/encoders could safely be inserted;
Insert the decoders/encoders at the chosen points;
Generate a file __dump__.c with the jitting code
for the function, plus instructions to dump the bytes for
each of the basic blocks we want to encode:
void foo(void) {
p6 = jit_init();
jit_add_prolog(p6, & _1_foo8___foo, 0);
localSize9 = jit_allocai(p6, 64L);
jit_add_op(p6, JIT_ADD | 2, ((2 << 4) | (1 << 2)) | 3, (0 & 1) | (((0 & 3) << 1) | ((1 & 268435455) << 4)),
(0 & 1) | (((2 & 3) << 1) | ((0 & 268435455) << 4)), (jit_value )(localSize9 + 44),
0L, 0);
jit_add_op(p6, JIT_MOV | 2, ((0 << 4) | (2 << 2)) | 3, (0 & 1) | (((0 & 3) << 1) | ((2 & 268435455) << 4)),
(jit_value )(& printf), 0L, 0L, 0);
jit_add_op(p6, JIT_ST | 1, ((0 << 4) | (1 << 2)) | 1, (0 & 1) | (((0 & 3) << 1) | ((1 & 268435455) << 4)),
(0 & 1) | (((0 & 3) << 1) | ((2 & 268435455) << 4)), 0L, 8, 0);
...
jit_generate_code(p6);
DUMP_byte(1, p6, block_1_BEGIN11, block_1_END12);
DUMP_byte(16, p6, block_16_BEGIN13, block_16_END14);
DUMP_byte(18, p6, block_18_BEGIN15, block_18_END16);
DUMP_byte(30, p6, block_30_BEGIN17, block_30_END18);
DUMP_byte(31, p6, block_31_BEGIN19, block_31_END20);
DUMP_byte(32, p6, block_32_BEGIN21, block_32_END22);
...
Compile and run __dump__.c, generating a file __dump__.blk
which has the raw bytes for every basic block:
BLOCK 1 byte 24 72 141 125 192 72 141 117 192 72 99 22 72 139 202 72 131 193 1 137 15 144 144 144 144 1 4
BLOCK 16 byte 32 72 141 125 192 72 99 55 72 131 254 50 72 186 0 0 0 0 0 0 0 0 64 15 156 194 72 141 77 252 137 17 144 1 4
BLOCK 18 byte 16 72 141 125 192 199 7 0 0 0 0 144 144 144 144 144 144 1 4
BLOCK 30 byte 72 72 141 125 200 72 141 117 244 72 139 22 72 139 10 72 141 17 72 137 23 72 141 125 208 72 141 117 192 72 99 22 137 23 72 141 125 236 72 139 55 72 141 85 208 72 99 10 76 141 69 200 77 139 8 72 137 117 168 72 139 241 73 139 249 51 192 255 85 168 144 144 144 1 4
BLOCK 31 byte 72 72 141 125 216 72 141 117 244 72 139 22 72 139 10 72 141 17 72 137 23 72 141 125 224 72 141 117 192 72 99 22 137 23 72 141 125 236 72 139 55 72 141 85 224 72 99 10 76 141 69 216 77 139 8 72 137 117 168 72 139 241 73 139 249 51 192 255 85 168 144 144 144 1 4
BLOCK 32 byte 24 72 141 125 228 72 139 55 72 141 85 228 72 139 10 76 99 1 77 141 72 2 68 137 14 1 4
Generate a file __encode__.c which contains all the raw bytes
from __dump__.blk and all the codecs (xor, xtea, etc). Compile
and run __encode__.c, generating a file __encode__.blk
which contains all the encoded basic blocks:
BLOCK 1 byte 24 0 150 40 158 183 11 243 58 110 209 29 153 124 46 18 14 10 27 97 227 92 19 80 246 0
BLOCK 16 byte 32 76 189 227 92 247 77 242 199 113 84 187 65 8 176 115 94 49 181 11 5 154 173 46 183 141 132 129 145 165 99 158 217 0
BLOCK 18 byte 16 183 246 223 30 130 212 211 84 33 153 30 177 219 142 103 219 0
BLOCK 30 byte 72 213 130 51 242 153 48 73 211 125 101 119 66 161 239 137 109 50 235 72 137 167 130 85 136 0 185 44 108 170 111 249 215 63 46 224 91 112 130 253 192 83 135 162 17 240 216 183 168 214 131 163 112 239 26 149 190 81 126 175 148 107 71 116 148 119 92 26 141 131 168 174 5 0
BLOCK 31 byte 72 65 152 118 67 241 118 153 110 125 101 119 66 161 239 137 109 134 95 82 37 197 146 236 96 0 185 44 108 170 111 249 215 63 46 224 91 112 130 253 192 30 208 93 201 186 163 9 173 170 211 3 162 223 85 230 104 81 126 175 148 107 71 116 148 119 92 26 141 131 168 174 5 0
BLOCK 32 byte 24 127 82 142 1 193 218 46 10 34 19 201 130 55 248 122 67 145 230 144 218 219 35 49 3 0
Replace the cleartext blocks in the CFG with their encoded
counterparts from __encode__.blk;
Simplify jumps and turn the CFG back into C source.
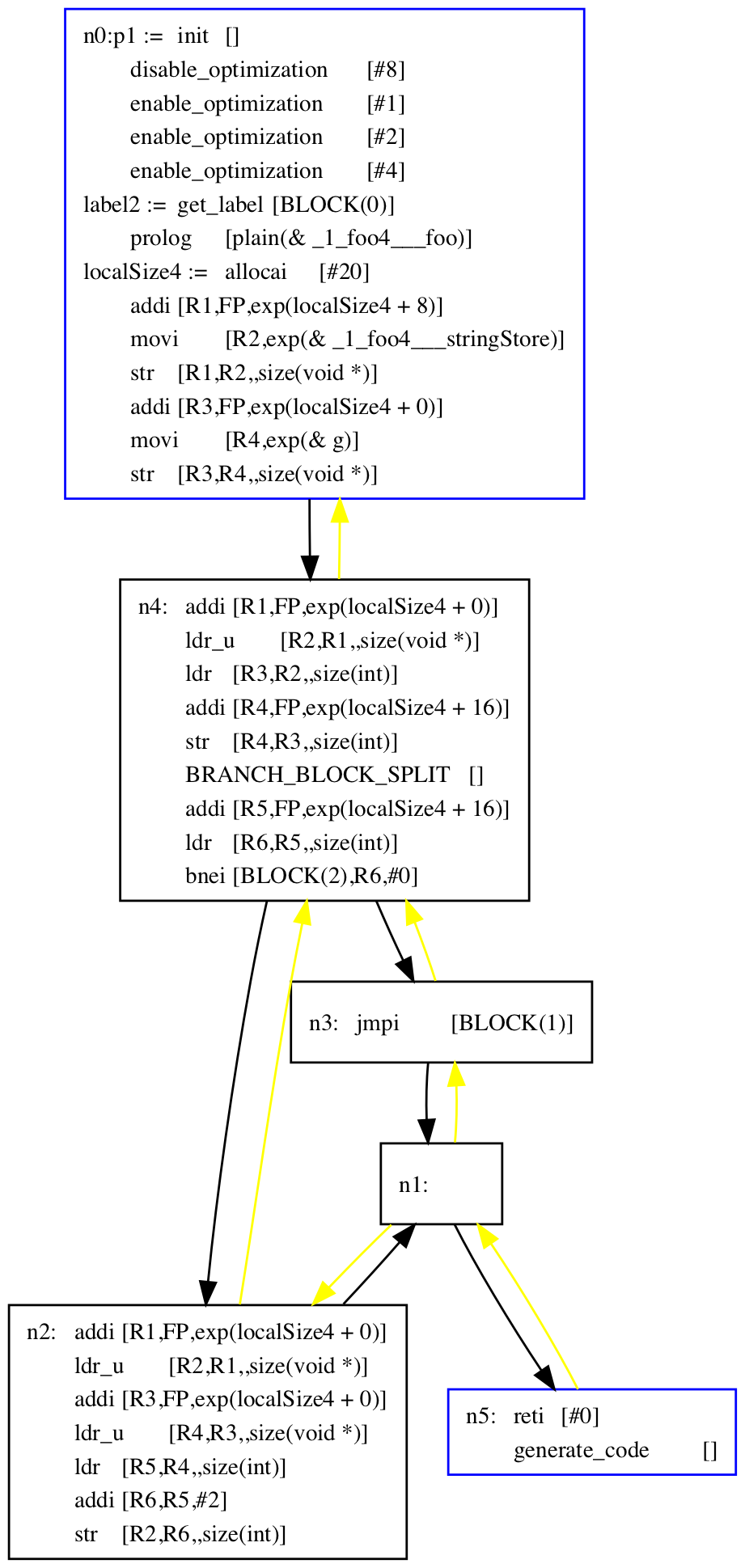
This function:
void foo4() {
if (g) {
g+=2;
};
}
turns into this CFG:
We then find points where blocks can be encoded and decoded, and insert annotations (left arrows for encode, right arrows for decode) into the CFG:
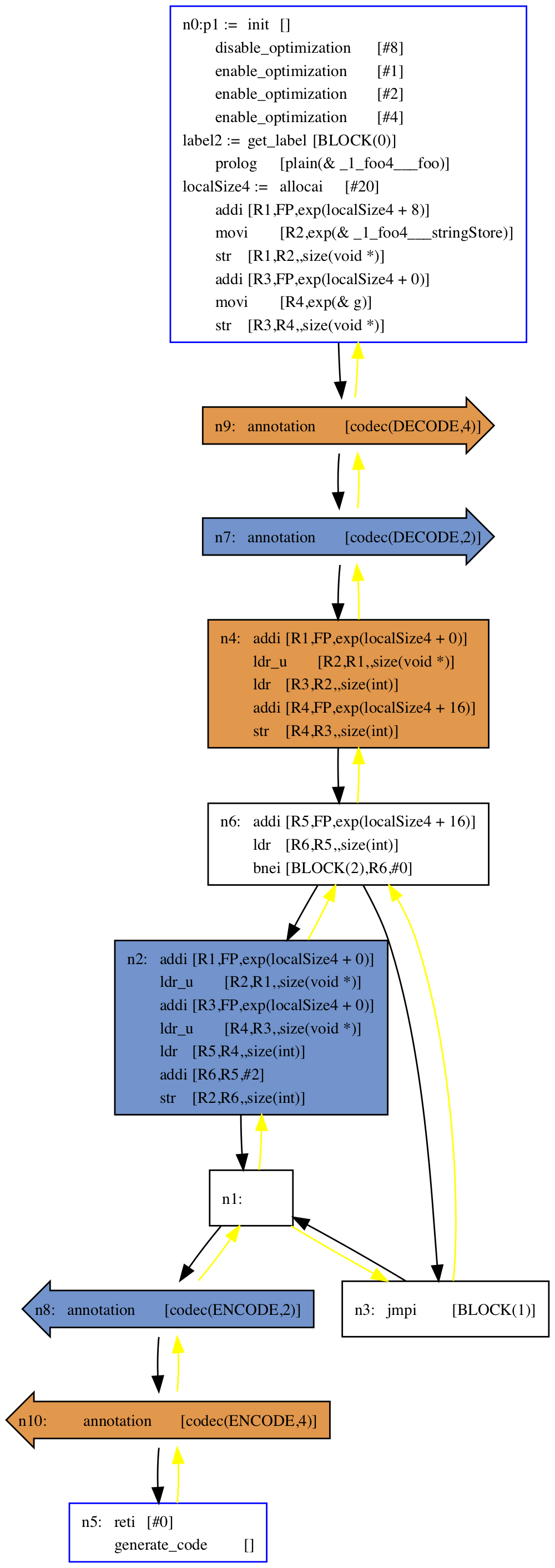
In this trivial CFG, the decoders/encoders are inserted at the beginning and end of the function but, in general, they are inserted randomly, subject to the constraint that when control reaches a block it should be in cleartext, and when the function returns every block should be encoded.
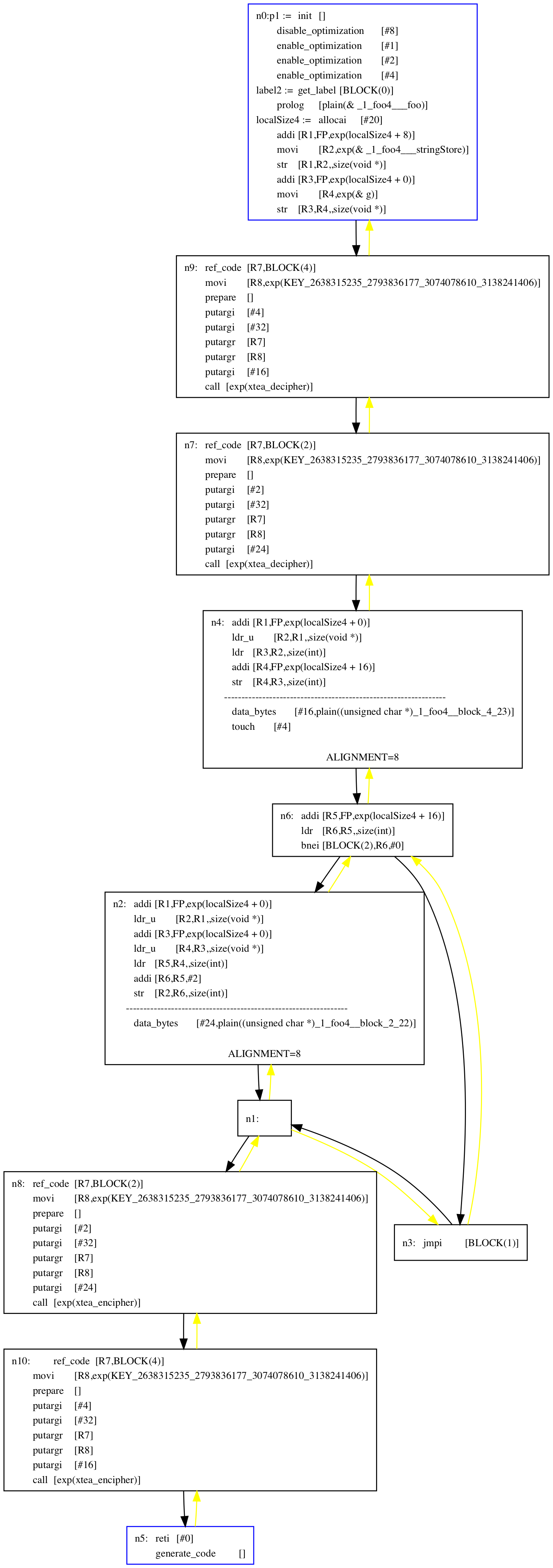
We next translate these annotations into the actual decoders/encoders (here, calls to the xtea decipher/encipher functions):
Finally, we replace cleartext code blocks with the corresponding encoded blocks:
The Dynamic transformation is built on the Jittransformation and therefore the Jit's usage applies to the Dynamic transformation as well. In particular, you have to add the appropriate directives to the top of your C source file to include the jitter.
A typical invokation of Tigress would look like this:
tigress \
--Transform=JitDynamic \
--Functions=foo \
--JitDynamicCodecs=xtea \
--JitDynamicDumpCFG=true \
--JitDynamicBlockFraction=%50 \
--out=f_out.c f.c
The issues for the Jit transformation apply to the Dynamic transformation as well.
Recursion is an issue for dynamic obfuscation. In general, whenever you call a function it has to be in its fully encoded form. This presents a problem if a function calls itself (directly or through a recursive call chain) from somewhere in the middle where some blocks are encoded and some are in cleartext. For simple recursive procedures we detect this and
In certain situations we won't detect the recursion and this will lead to bad code being generated:
The good news is that an obfuscated program that violates these rules will probably crash quickly since the resulting code will try to execute an encoded block.
Performance of Tigress itself can be a problem. The issue is finding the positions in the control flow graph where we can insert codecs. There are two problems:
--Verbosity=5 to see what's happening,
and then set --JitDynamicBlockFraction=%10, for example, to cut down on
the number of blocks that get encoded.