inserting bogus instructions between consecutive iterations of the dispatch loop, thereby making the dispatch harder to recognize;
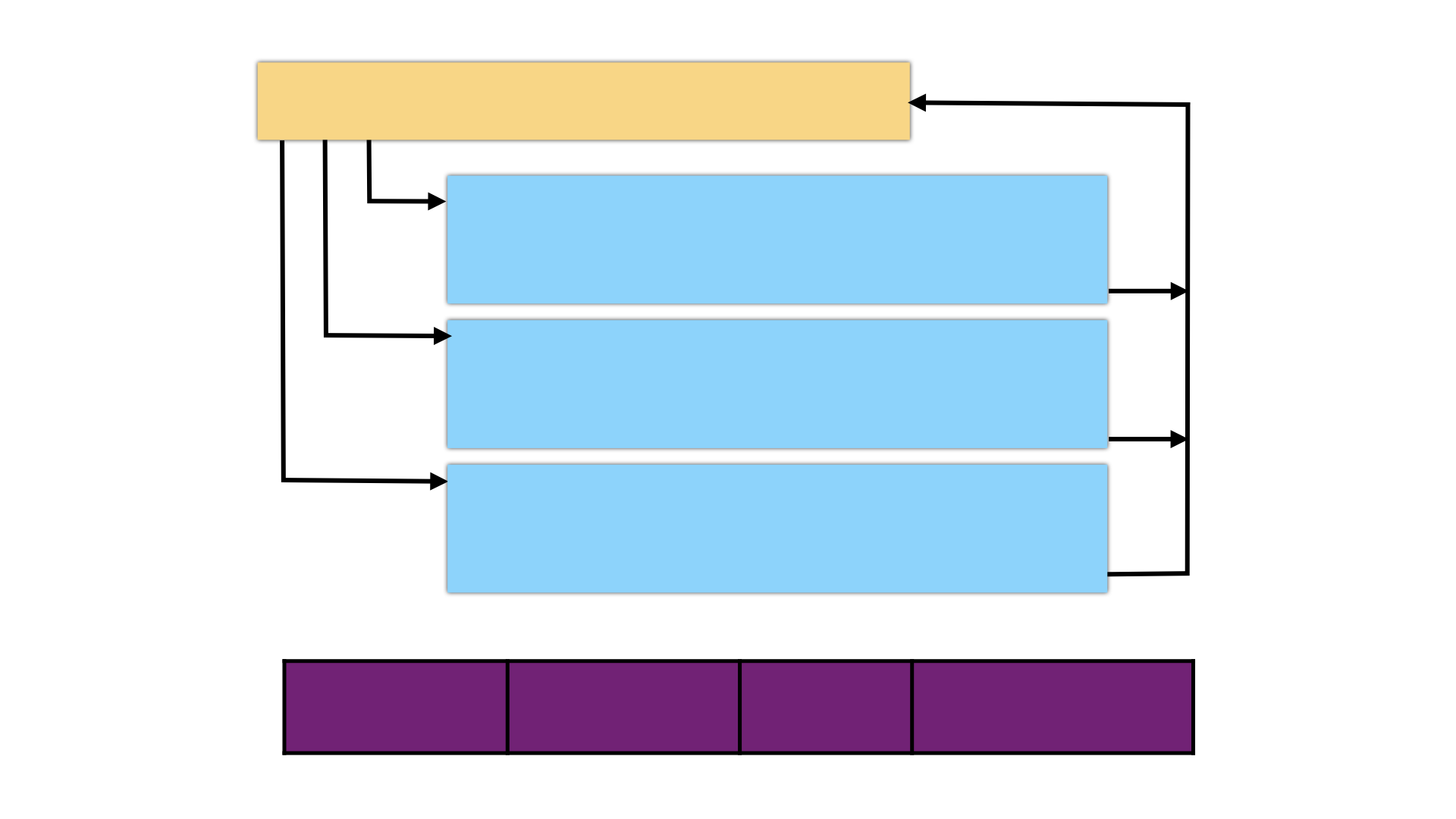
This transformation turns a function into an interpreter, whose bytecode language is specialized for this function. The transformation has been designed to induce as much diversity as possible, i.e. every decision made is dependent on the randomization seed. The diversity is both static and dynamic, i.e. each interpreter variant differs in the structure of its code as well as in its execution pattern.
A generated interpreter consists of a virtual instruction set, specialized for the input function, a bytecode array, a virtual program counter (VPC), a virtual stack pointer (VSP), a dispatch unit, and a list of instruction handlers, one for each virtual instruction.
Here is a LigerLabs video that gives a good introduction to the virtualization obfuscation:
Here's an example of an interpreter constructed by Tigress for the program
main(){int x; x++;}:
enum ops {Locals = 116, Plus = 135, Load = 60, Goto = 231,
Const = 3, Store = 122, Return = 72};
unsigned char bytecode[41] = {
Locals,24,0,0,0,Const,1,0,0,0,Locals,24,0,0,0,Load,Plus,Store,Locals,
28,0,0,0,Const,0,0,0,0,Store,Goto,4,0,0,0,Locals,28,0,0,0,Load,Return};
int main() {
while (1) {
switch (*pc) {
case Const: pc++; (sp+1)->_int = *((int *)pc); sp++; pc+=4; break;
case Load: pc++; sp->_int = *((int *)sp->_vs); break;
case Goto: pc++; pc+= *((int *)pc); break;
case Plus: pc++; (sp+-1)->_int=sp->_int+(sp+-1)->_int; sp--; break;
case Return: pc++; return (sp->_int); break;
case Store: pc++; *((int *)(sp+-1)->_vs)=sp->_int; sp+=-2; break;
case Locals: pc++; (sp+1)->_vs=(void *)(vars+*((int *)pc));
sp++; pc+=4; break;
}}
For this transformation, Tigress first constructs type-annotated abstract syntax tree (AST) from the C source, from which it generates control-flow graphs of instruction trees. Tigress then selects a random instruction set architecture (ISA) and, using this ISA, generates a bytecode program specialized for the input function. Finally, Tigress selects a random dispatch method and produces an output program.
Static diversity. Tigress supports two mechanisms for generating ISAs with a high degree of static diversity:
Dynamic diversity. We ensure that dynamic execution patterns are diversified by merging randomized bogus functions with the ``real'' function. We can furthermore impede dynamic analysis by making instruction traces artificially long.
Static stealth.
Not only diversity but also stealth is important for
interpreters. For static stealth, the split transformation can break up the
interpreter loop into smaller pieces, and the AddOpaque
transformation can make instruction handlers less conspicuous.
Dynamic stealth. For dynamic stealth, Tigress interpreters can be made reentrant, meaning only a few iterations of the dispatch loop are executed at a time, effectively mixing instructions executed from the interpreter with instructions executed by the rest of the program. This is of particular interest when wanting to hide the execution pattern from analysts, and when the exact time that the function executes is not important, as long as it completes eventually.
Here is a LigerLabs video that presents some of protections against attack that can be added to an obfuscated interpreter:
A typical call to Tigress to virtualize a function foo looks like this:
tigress \
--Environment=x86_64:Linux:Gcc:4.6 \
--Transform=Virtualize \
--Functions=foo \
--VirtualizeDispatch=direct \
--out=out.c in.c
And here are the options for debugging and optimization:
| Option | Arguments | Description |
|---|---|---|
| --Transform | Virtualize | Turn a function into an interpreter. |
| --VirtualizeShortIdents | bool | Generate shorter identifiers to produce interpreters suitable for publication. Default=false. |
| --VirtualizePerformance | IndexedStack, PointerStack, AddressSizeShort, AddressSizeInt, AddressSizeLong, CacheTop | Tweak performance. A comma-separated list of the options below. MODIFIES Virtualize DEFAULT PointerStack
|
| --VirtualizeOptimizeBody | BOOLSPEC | Clean up after superoperator generation by optimizing the body of the generated function. Default=false. |
| --VirtualizeOptimizeTreeCode | BOOLSPEC | Do constant folding etc. prior to interpreter generation. Default=false. |
| --VirtualizeTrace | instr, args, stack, checkTags, actions, regs, locals, checkLocals, threads, * | Insert tracing code to show the stack and the virtual instructions executing. Default=print nothing.
|
| --VirtualizeTaggedStore | BOOLSPEC | Make stack and registers tagged with their type. Useful for debugging. Default=false. |
| --VirtualizeStackSize | INTSPEC | Number of elements in the evaluation stack. Default=32. |
| --VirtualizeComment | bool | Insert comments in the generated interpreter. Default=false. |
| --VirtualizeDump | input, tree, ISA, instrs, types, vars, strings, SuperOps, calls, bytes, array, stack, * | Dump internal data structures used by the virtualizer. Comma-separated list. Default=dump nothing.
|
| --VirtualizeConditionalKinds | branch, compute, flag | Ways to transform the one conditional branch that occurs in instruction handlers. Default=branch.
|
For both static and dynamic diversity, Tigress supports nine different
dispatch methods. The following code is generated for the different methods,
where Ξop1; is the instruction handler for
operator op1:
| Dispatch | Generated code |
|---|---|
switch |
|
direct |
|
indirect |
|
call |
|
ifnest |
|
linear, binary, interpolation |
|
Tigress also supports concurrent dispatch, which is a variant of switch dispatch, where every iteration
around the interpreter loop is split between a number of concurrently executing threads. It's specified like this:
--VirtualizeDispatch=concurrent --VirtualizeNumberOfThreads=2.
To further confuse static analysis, in an direct and indirect threaded dispatch loop you can make every indirect jump go through a branch function. It is specified like this:
--Transform=InitBranchFuns \
--InitBranchFunsCount=1 \
... \
--Transform-Virtualize \
--VirtualizeDispatch=direct \
--VirtualizeBranchFunctions=true
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeDispatch | switch, direct, indirect, call, ifnest, linear, binary, interpolation, concurrent, ?, * | Select the interpreter's dispatch method. The argument should be a comma-separated list of disparch kinds. One of these will be picked at random. Default=switch.
|
| --VirtualizeNumberOfThreads | INTSPEC | Number of threads to spawn when using concurrent dispatch. Default=2. |
| --VirtualizeBranchFunctions | BOOLSPEC | Make every dispatch jump go through a branch function. This only applies to direct and indirect threaded dispatch. Requires --Transform=InitBranchFuns --InitBranchFunsCount=1. Default=false. |
Instruction sets can use stacks, registers, or both to pass values between instructions. By default, the following, very simple, instruction set is used:
labels: l ∈functions: f ∈Labels Funs variables: x ∈Vars strings: s ∈Strings temporaries: t ::=regint |stackint binary operators:binop ::=add|sub| … unary operators:unop ::=uminus|neg| … types: τ ::=int|float| … |void *literals: λ ::=intlit|floatlit| … instructions: e ::= t ←constantτ λ | t ←localx | t ←globalx | t ←formalx | t ←strings | t ←binaryτbinop t t | t ←unaryτunop t | t ←convertτ τ t | t ←ternaryτ t t t | t ←loadτ t |storeτ t t | t ←memcpyt tint |callf | x, x, ←asms t, t, … |indirectCallt |returnτ t |gotol | t ←addrOfLabell |indirectGotot |branchIfTruet l |switchτ t λ λ l ⟨l, l, …⟩ |merged⟨ e, e, \ldots⟩
However, a high degree of diversity can be achieved from the way instructions communicate with each other, through values stored on the stack or passed in virtual registers. Tigress can generate instructions that use any combination of registers and stack storage for the inputs they read or the output they produce.
Tigress can induce further diversity by merging instructions into superoperators. New, merged, instructions can have an almost abritrary complex semantics, involving multiple arithmetic operations and operations both on the stack and virtual registers. For more information on superoperators, see Optimizing an ANSI C interpreter with superoperators by Todd Proebsting. The complex semantics of instructions generated by superoperators make manual analysis of generated interpreters, such as discussed by Rolles in Unpacking virtualization obfuscators, difficult.
Consider setting --VirtualizeMaxDuplicateOps=2
and --VirtualizeOperands=mixed resulting in two store-int
instructions, one that takes both arguments in registers, and one that takes
one argument on the stack and the other in a register. Tigress will chose
between them randomly. Here are the corresponding instruction handlers:
case _0__store_int$left_REG_0$right_REG_1:
(_0__pc[0]) ++;
*((int *)_0__regs[0][*((int *)_0__pc[0])]._void_star) = _0__regs[0][*((int *)(_0__pc[0] + 4))]._int;
_0__pc[0] += 8;
break;
case _0__store_int$right_STA_0$left_REG_0:
(_0__pc[0]) ++;
*((int *)_0__regs[0][*((int *)_0__pc[0])]._void_star) = _0__stack[0][_0__sp[0] + 0]._int;
(_0__sp[0]) --;
_0__pc[0] += 4;
break;
Consider next setting --VirtualizeSuperOpsRatio=2.0 and --VirtualizeMaxMergeLength=10,
resulting in virtual instructions with highly complex semantics:
Here is the instruction handler for one such instruction, made up by merging 10 primitive instructions:
case _0__local$result_STA_0$value_LIT_0__\
convert_void_star2void_star$left_STA_0$result_REG_0__\
load_int$result_REG_0$left_REG_1__\
local$result_STA_0$value_LIT_0__\
convert_void_star2void_star$left_STA_0$result_REG_0__\
store_int$left_REG_0$right_REG_1__\
local$result_REG_0$value_LIT_1__\
local$result_STA_0$value_LIT_0__\
convert_void_star2void_star$left_STA_0$result_REG_0__\
load_int$result_STA_0$left_REG_0:
(_0__pc[0]) ++;
_0__regs[0][*((int *)(_0__pc[0] + 4))]._void_star = (void *)(_0__locals + *((int *)_0__pc[0]));
_0__regs[0][*((int *)(_0__pc[0] + 8))]._int = *((int *)_0__regs[0][*((int *)(_0__pc[0] + 12))]._void_star);
_0__regs[0][*((int *)(_0__pc[0] + 20))]._void_star = (void *)(_0__locals + *((int *)(_0__pc[0] + 16)));
*((int *)_0__regs[0][*((int *)(_0__pc[0] + 24))]._void_star) = _0__regs[0][*((int *)(_0__pc[0] + 28))]._int;
_0__regs[0][*((int *)(_0__pc[0] + 32))]._void_star = (void *)(_0__locals + *((int *)(_0__pc[0] + 36)));
_0__regs[0][*((int *)(_0__pc[0] + 44))]._void_star = (void *)(_0__locals + *((int *)(_0__pc[0] + 40)));
_0__stack[0][_0__sp[0] + 1]._int = *((int *)_0__regs[0][*((int *)(_0__pc[0] + 48))]._void_star);
(_0__sp[0]) ++;
_0__pc[0] += 52;
break;
Note that the instruction name really is almost 400 characters long; the
backslashes are here only for display purposes! Also note that the instruction
itself is 53 bytes long, almost as long as the
longest VAX instruction
(EMODH, 54 bytes) and much longer than the longest x86 instruction
(15 bytes)
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeOperands | stack, registers, mixed, ? | Comma-separated list of the types of operands allowed in the ISA. Default=stack.
|
| --VirtualizeMaxDuplicateOps | INTSPEC | Number of ADD instructions, for example, with different signatures. Default=0. |
| --VirtualizeRandomOps | bool | Should opcodes be randomized, or go from 0..n? Default=true. |
| --VirtualizeSuperOpsRatio | Float>0.0 | Desired number of super operators. Default=0.0. |
| --VirtualizeMaxMergeLength | INTSPEC | Longest sequence of instructions to be merged into one. Default=0. |
You can split up the generated interpreter by inserting opaque predicates. This is useful to make the instruction handlers and the dispatch logic less conspicuous. Here's one example; the handler can obviously be split in multiple ways:
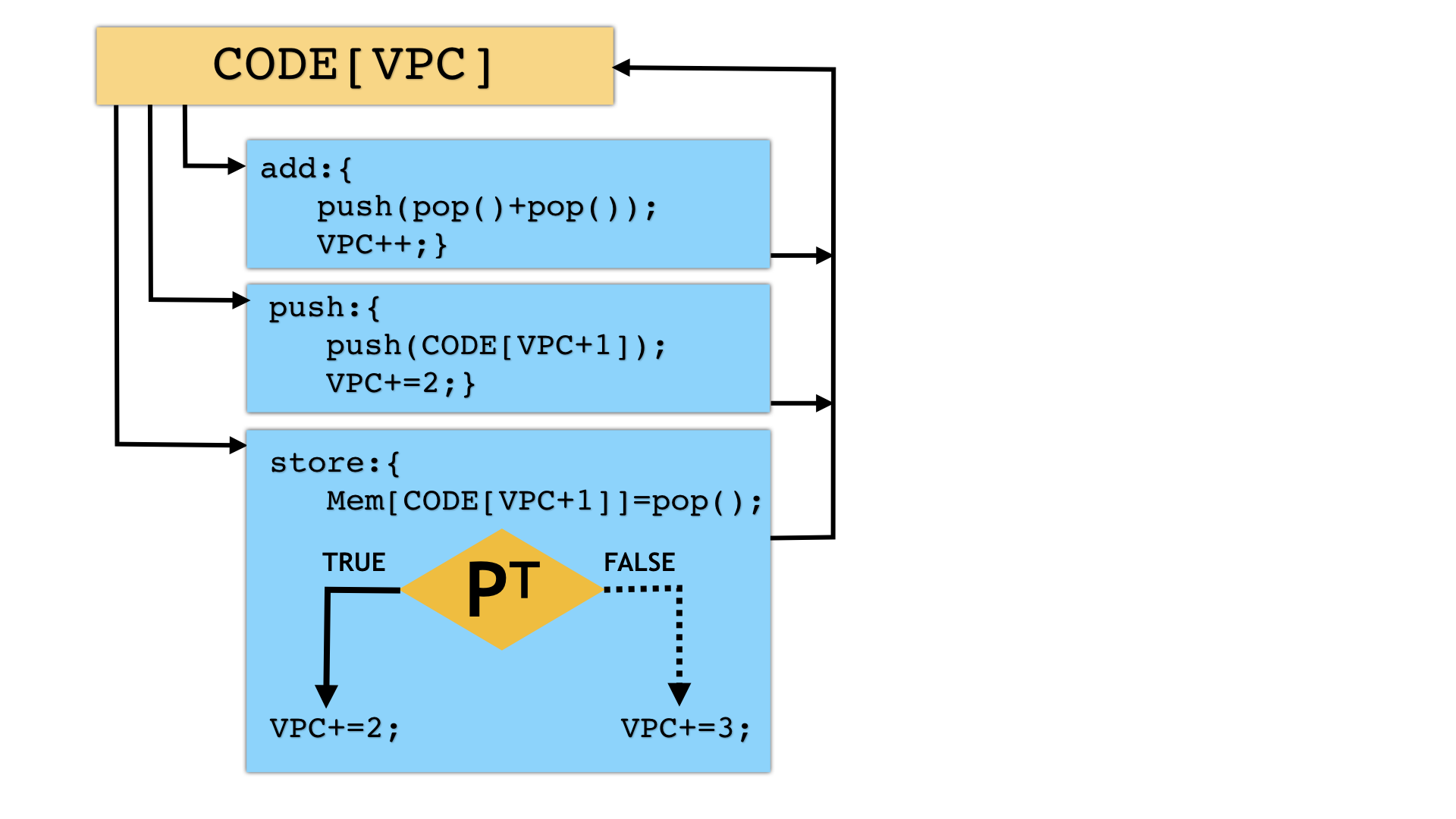
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeInstructionHandlerSplitCount | INTSPEC | Number of opaques to add to each instruction handler. Default=0. |
You can add opaque expressions to the virtual PC to make it more difficult to find.
One possible attack on interpreters is to perform a taint analysis on input-dependent variables and discard any instructions which are not tainted. To frustrate such analyses we can add implicit flow to the VPC.
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeAddOpaqueToVPC | BOOLSPEC | Whether to add opaques to the virtual program counter. Default=false. |
| --VirtualizeImplicitFlowPC | PCInit, PCUpdate, * | Insert implicit flow between the virtual program counter and instruction dispatcher. Default=none.
|
| --VirtualizeImplicitFlow | S-Expression | The type of implicit flow to insert. See --AntiTaintAnalysisImplicitFlow for a description. Default=none. |
Generate bogus functions that are virtualized along with the "real" function. Instructions from the bogus and real function are executed cyclically and in sequence, i.e. first an instruction from the real function, then one from bogus function number 1, then one from bogus function number 2, etc., and then the process repeats with an instruction from the real function. The purpose is to frustrate dynamic analyses that try to locate the virtual program counter, by providing multiple VPCs, one "real", and one or more that behave as if they were real, but which interpret unused functions:
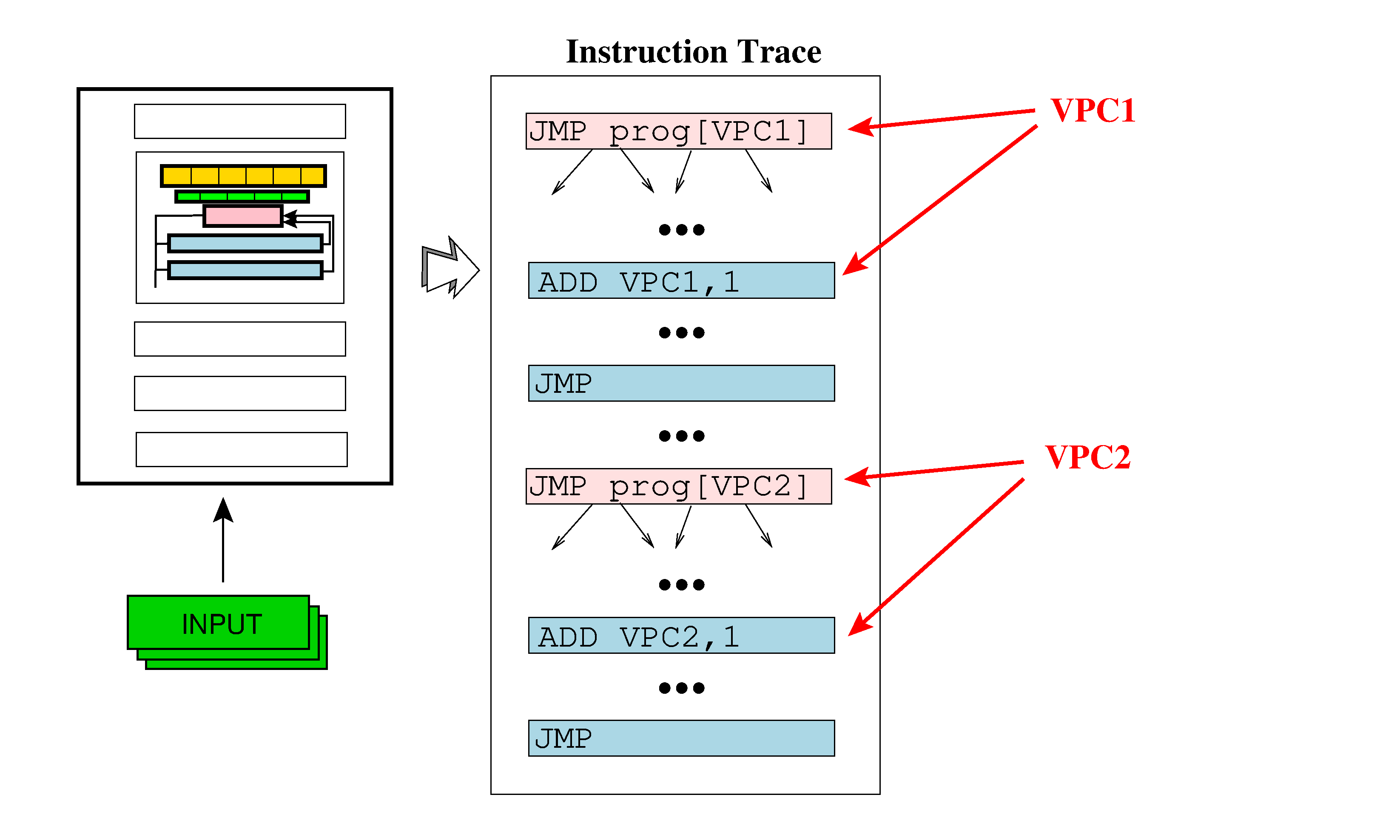
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeNumberOfBogusFuns | INTSPEC | Weave the execution of random functions into the execution of the original program. This makes certain kinds of pattern-based dynamic analysis more difficult. Default=0. |
| --VirtualizeAddOpaqueToBogusFuns | BOOLSPEC | Whether to add opaque expressions to the generated bogus function. Default=false. |
| --VirtualizeBogusFunsGenerateOutput | BOOLSPEC | Make the bogus function produce output (typically be writing to /dev/null), to prevent it from appearing to have no effect. Default=true. |
| --VirtualizeBogusFunKinds | trivial, arithSeq, collatz, * | The kind of bogus function to generate. Comma-separated list. Default=arithSeq,collatz.
|
Add random computations to every iteration of the dispatch loop. Use this to frustrate dynamic analysis by
inserting bogus instructions between consecutive iterations of the dispatch loop, thereby making the dispatch harder to recognize;
making traces longer and thereby harder to store and analyze.
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeBogusLoopKinds | trivial, arithSeq, collatz, * | Insert a bogus loop for each instruction list. This will extend the length of the trace, making dynamic analysis more difficult. Default=collatz.
|
| --VirtualizeBogusLoopIterations | INTSPEC | Adjust this value to balance performance and trace length. Default=0. |
Make interpreters that can execute a few instructions, return, and later resume to execute a few more instructions, until, eventually, they terminate. This is particularly useful when it is not important exactly when the a piece of code executes, as long as it executes eventually, and where the stealthiness of the computations is paramount.
You must prepare your code in the following ways:
The function you want to virtualize must have an argument
int* operation. It can occur anywhere among the formal parameters:
void foo(int* operation, int n, int* result) {…}
The first time foo gets called, operation must be <0, and you must pass actual arguments to foo that it will use throughout the computation:
int operation = -10;
foo(&operation,n,&result);
Sprinkle calls to foo throughout your program, making sure that operation>0:
operation = 10;
foo(&operation,bogus1,&bogus2);
You can check if foo has terminated by testing the
value of operation after the call:
operation = 10;
foo(&operation,bogus1,&bogus2);
if (operation > 0)
/* we're done! */
else if (operation < 0)
/* more work to do! */
If you want to make sure that foo has terminated --- because you really want its result at a particular point --- set operation to a large enough value:
operation = 1000;
foo(&operation,bogus1,&bogus2);
Additional calls to foo once termination has been reached is safe; no additional instructions will be executed.
If you want to call foo to compute a new value, call it again with operation<0:
int operation = -10;
foo(&operation,n,&result);
To ensure termination you can
experiment yourself with how many iterations are necessary to finish the computation;
make sure that the last call to foo is passed a huge value to 'operation';
put the last call to foo in a loop
foo(&operation);
while (operation < 0) {
/* some other computation here */
operation = 10;
foo(&operation);
}
/* result is available here */
It is a good idea to combine reentrant interpreters with superoperators. Superoperators produce long instructions that perform more work during each iteration, and as a result the number of dispatches (i.e. loop iterations) is reduced. In other words, if you want to frustrate dynamic analysis that looks for evidence of the dispatch loop in the instruction trace, superoperators combined with reentrant interpreters will reduce the presence of such artifacts.
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeReentrant | Make the function reentrant. Default=false. |
Setting
--VirtualizeEncodeByteArray=allAtOnce
results in each program instruction being xor:ed with
a constant value, thus ensuring that it is
not in cleartext until it is run. The generated code
looks something like this:
unsigned char _5_obf3_$array[1][141] =
{{
(unsigned char)formal$result_STA_0$value_LIT_0 ^ (unsigned char)16,
(unsigned char)1 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)load_int$left_STA_0$result_STA_0 ^ (unsigned char)16,
(unsigned char)formal$result_STA_0$value_LIT_0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
(unsigned char)0 ^ (unsigned char)16,
...
}}
This does not work for --VirtualizeDispatch=direct.
Additionally, setting --VirtualizeObfuscateDecodeByteArray=true and
--VirtualizeOpaqueStructs=input,env ensures that the decoded
bytecode array depends on input. The decoding procedure looks like this:
strcmp_result17 = (int)strlen(*(argv + (argc - 1)));
decodeVar16 = (strcmp_result17 - 1 < 0) + (strcmp_result17 - 10 > 0) ? currentOp : (unsigned char)16;
copyIndex15 = 0;
while (copyIndex15 < 141) {
localArrayCopy11[0][copyIndex15] = array[0][copyIndex15] ^ decodeVar16;
copyIndex15 ++;
}
$pc[0] = localArrayCopy11[0];
Here's an example script:
tigress --Environment=... --Seed=0 \
--Transform=InitImplicitFlow \
--Transform=InitEntropy \
--Transform=InitOpaque --Functions=main --InitOpaqueStructs=input \
--Transform=UpdateEntropy --Functions=main --UpdateEntropyVar=argv,argc \
--Inputs="+1:int:42,-1:length:1?10" \
--Transform=Virtualize --InitOpaqueStructs=input,env \
--VirtualizeDispatch=interpolation --Functions=obf3 \
--VirtualizeEncodeByteArray=allAtOnce \
--VirtualizeObfuscateDecodeByteArray=true \
--VirtualizeOpaqueStructs=input,env \
arith.c --out=arith_out.c
--Inputs="+1:int:42,-1:length:1?10" is a specfication of invariants over
the command line. It specifies:
--VirtualizeOpaqueStructs=input,env ensures that the
program array will be encoded based on these command line invariants.
If the program is invoked with a set of command line arguments that
violate the invariants it is likely to crash.
Starting with version 3.3.3, setting --VirtualizeEncodeByteArray=incrementally results in
the bytecode array being decoded as each entry is encountered. The instruction handler
code now looks like this, where 3472328296227680304UL is the xor encoding constant:
__4_callInd__constant_unsigned_long$result_STA_0$value_LIT_0: ;
(__4_callInd_$pc[0]) ++;
(__4_callInd_$sp[0] + 1)->_unsigned_long = *((unsigned long *)__4_callInd_$pc[0]) ^ 3472328296227680304UL;
(__4_callInd_$sp[0]) ++;
__4_callInd_$pc[0] += 8;
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeOpaqueStructs | list, array, input, env, * | Default=list,array.
|
| --VirtualizeEncodeByteArray | allAtOnce, incrementally | Encode the bytecode array. Doesn't work for direct dispatch. Requires opaque expressions. Prior to version 3.3.3 this used to be a boolean, which triggered allAtOnce. Default=NONE.
|
| --VirtualizeObfuscateDecodeByteArray | BOOLSPEC | Obfuscates the program array decoded with opaque expressions. --VirtualizeOpaqueStructs=input,env are the preferable opaque kinds, since it means that the bytecode array depends on input. Default=false. |
Setting --VirtualizeDynamicBytecode=true
results in the program array being constantly modified at runtime,
much in the same way that happens to jitted code in the
JitDynamic
transformation. In fact, exactly the same mechanisms are used
for both transformations, and they share all the same options.
Here's an example script:
tigress --Seed=0 \
--Transform=Virtualize \
--Functions=foo \
--VirtualizeDispatch=switch \
--VirtualizeDynamicBytecode=true \
--VirtualizeDynamicCodecs=xtea \
--VirtualizeDynamicKeyTypes=data \
--VirtualizeDynamicBlockFraction=%100 \
--VirtualizeDynamicReEncode=true \
--VirtualizeDynamicRandomizeBlocks=false \
--VirtualizeDynamicDumpCFG=false \
--VirtualizeDynamicAnnotateTree=false \
--VirtualizeDynamicDumpTree=false \
--VirtualizeDynamicDumpIntermediate=false \
--VirtualizeDynamicTrace=0 \
--VirtualizeDynamicTraceExec=false \
--VirtualizeDynamicTraceBlock=false \
--VirtualizeDynamicCompileCommand="gcc -o %o %i -lm" \
arith.c --out=arith_out.c
| Option | Arguments | Description |
|---|---|---|
| --VirtualizeDynamicBytecode | BOOLSPEC | Similar to the JitDynamic transform, make the virtualized bytecode self-modifying. Default=false. |
| --VirtualizeDynamicOptimize | BOOLSPEC | Clean up the generated code by removing jumps-to-jumps. Default=true. |
| --VirtualizeDynamicTrace | INTSPEC | Insert runtime tracing of instructions. Set to 1 to turn it on. Default=0. |
| --VirtualizeDynamicTraceExec | BOOLSPEC | Annotate each instruction, showing from where it was generated, and the results of execution. Default=false. |
| --VirtualizeDynamicDumpTree | BOOLSPEC | Print the tree representation of the function, prior to generating the jitting code. Default=false. |
| --VirtualizeDynamicAnnotateTree | BOOLSPEC | Annotate the generated code with the corresponding intermediate tree code instructions. Default=false. |
| --VirtualizeDynamicCodecs | none, ident, ident_loop, xor_transfer, xor_byte_loop, xor_word_loop, xor_qword_loop, xor_call, xor_call_trace, xtea, xtea_trace, stolen_byte, stolen_short, stolen_word | How blocks should be encoded/decoded. Default=*.
|
| --VirtualizeDynamicKeyTypes | data, code | Where the encoding/decoding key is stored (for xor and xtea encodings) Default=data.
|
| --VirtualizeDynamicBlockFraction | FRACSPEC | Fraction of the basic blocks in a function to encode Default=all. |
| --VirtualizeDynamicRandomizeBlocks | BOOLSPEC | Randomize the order of basic blocks Default=true. |
| --VirtualizeDynamicReEncode | BOOLSPEC | If true, blocks will be re-encoded after being executed. If false, blocks will be decoded once, and stay in cleartext. ('False' is not implemented; this option is always set to 'true'.) Default=true. |
| --VirtualizeDynamicDumpCFG | BOOLSPEC | Print the jitter's Control Flow Graph. This requires graphviz to be installed (the dot command is used). A number of pdf files get generated that shows the CFG at various stages of processing: CFGAfterInsertingAnnotations.pdf, CFGAfterSimplifyingJumps.pdf, CFGAfterTranslatingAnnotations.pdf, CFGBeforeInsertingAnnotations.pdf, CFGDumpingFunctionFinal.pdf, CFGDumpingFunctionInitial.pdf, CFGFixupIndirecJumps.pdf, CFGReplaceWithCompiledBlock.pdf, CFGSplitOutBranches.pdf, CFGSplitOutDataReferences.pdf, OriginalCFG.pdf Default=false. |
| --VirtualizeDynamicTraceBlock | BOOLSPEC | Print out a message before each block is executed. Default=false. |
| --VirtualizeDynamicTraceBlock | STRING | Print out a message before each block is executed. (Not currently implemented.) Default="". |
| --VirtualizeDynamicCompileCommand | STRING | A string of the form "gcc -std=c99 -o %o %i", where "%i" will be replaced with the name of the input file and "%o" with the name of the output file. For example, if your program uses the math library, you should set --VirtualizeDynamicCompileCommand="gcc -std=c99 -o %o %i -lm". Default="gcc -std=c99 -o %o %i". |
You can virtualize a piece of a function, rather than the whole thing. Simpy put the name of the region after the function name, like this:
tigress ... --Transform=Virtualize --Functions=fac:region2 ...
The region has to be defined like this in the code:
void fac(int n) {
int s=1;
int i;
for (i=2; i<=n; i++) {
TIGRESS_REGION(region2,
s *= i;
);
}
printf("fac(%i)=%i\n",n,s);
}
Note that the region needs to be ``self-contained,'' i.e. you can't jump into it, or out of it. Also, there will be some performance overhead.
As you are reading the code, there are a couple of interesting things to note:
direct and call dispatch methods result
in much larger bytecode programs than the other methods. This
is particularly evident on 64-bit machines where every opcode
gets encoded in 8 bytes, in contrast with a single byte for
the other methods. For this reason, if you are contemplating
using two levels of interpretation, it's a good idea to make
the second level not use direct or call
dispatch, to keep the size of the program down. Future versions
of Tigress will use more compact encodings for these types of
dispatch.
Here are some of the known issues with the Virtualize transformation:
gcc's and clang
labels-as-values. For other compilers only
the switch and ifnest dispatch methods should be
used.
--VirtualizeEncodeByteArray=true does not work for the direct
dispatch method.
--VirtualizeConditionalKinds=flag option seems to have
multiple issues on MacOS/llvm. Presumably this is due to some compiler
problem related to inline assembly.
comp-goto-1.c torture test:
goto *(base_addr + insn.f1.offset);
alloca. Depending on the
platform and the size of the arrays, the generated code can blow out the stack, and the program willcrash.
If so, try the option
--TransformVLA=malloc which converts VLAs to calls to malloc/free instead.