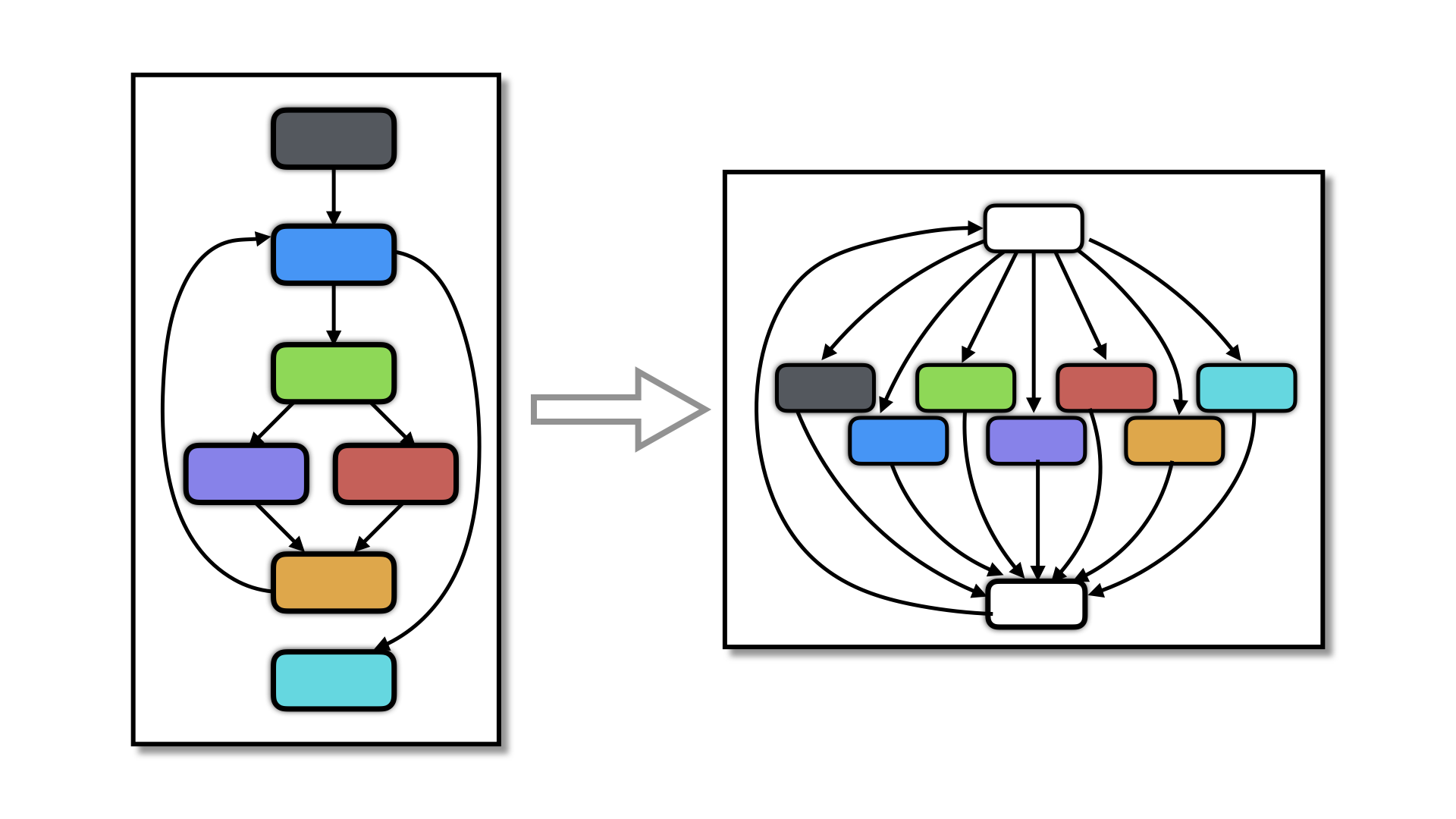
Control flow flattening is a classic control-flow transformation that removes structured control flow.
Here is a LigerLabs video that gives a good introduction to the flatten obfuscation:
Flattening is useful as a precursor to other transformations. For example, our AntiBranchAnalysis transformation flattens a function prior to replacing direct branches by calls to a branch function since this creates more opportunities for encoding. Also, the Merge transformation can optionally flatten functions before merging them, thus more thoroughly mixing their code.
| Option | Arguments | Description |
|---|---|---|
| --Transform | Flatten | Flatten a function using Chenxi Wang's algorithm |
| --FlattenDumpBlocks | BOOLSPEC | Print the linearized blocks. Default=false. |
| --FlattenSplitBasicBlocks | BOOLSPEC | If true, then basic blocks (sequences of assignment and call statements without intervening branches) will be split up into indiviual blocks. If false, they will be kept intact. Default=false. |
| --FlattenRandomizeBlocks | BOOLSPEC | If true, then basic block sequences will be randomized. Default=false. |
| --FlattenTrace | blocks, check, * | Print a message before each block gets executed. Useful for debugging. Prior to version 3.3.3 this used to be a boolean. Default=print nothing.
|
There are several sources of diversity:
next variable can be obfuscated using different kinds of opaque predicates.
These are the four basic kinds of block dispatch we currently support, and what a reursive factorial function looks like after transformation:
int fac(int x) {
int tmp ;
unsigned long next ;
next = 4;
while (1) {
switch (next) {
case 4:
if (x == 1) {
next = 3;
} else {
next = 2;
}
break;
case 3: return (1); break;
case 2: tmp = fac(x - 1); next = 1; break;
case 1: return (x * tmp); break;
}
}
}
int fac(int x) {
int tmp ;
goto lab4;
lab4:
if (! (x == 1)) {
goto lab2;
}
lab3:
return (1);
lab2:
tmp = fac(x - 1);
goto lab1;
lab1:
return (x * tmp);
}
int fac(int x) {
int tmp ;
unsigned long next ;
static void *jumpTab[4] = {&& lab1, && lab2, && lab3, && lab4};
next = 4;
goto *(jumpTab[next - 1]);
lab4:
if (x == 1) {
next = 3;
} else {
next = 2;
}
goto *(jumpTab[next - 1]);
lab3:
return (1);
goto *(jumpTab[next - 1]);
lab2:
tmp = fac(x - 1);
next = 1;
goto *(jumpTab[next - 1]);
lab1:
return (x * tmp);
goto *(jumpTab[next - 1]);
}
struct argStruct {
int tmp ;
int *x ;
int returnv ;
unsigned long next ;
};
void block_1(struct argStruct *arg ) {
arg->returnv = *(arg->x) * arg->tmp;
arg->next = 5;
return;
}
void block_2(struct argStruct *arg ) {
arg->tmp = fac(*(arg->x) - 1);
arg->next = 1;
return;
}
void block_4(struct argStruct *arg ) {
if (*(arg->x) == 1) {
arg->next = 3;
} else {
arg->next = 2;
}
return;
}
void block_3(struct argStruct *arg ) {
arg->returnv = 1;
arg->next = 5;
return;
}
int fac(int x ){
struct argStruct arg ;
static void (*jumpTab[4])(struct argStruct *arg ) = {& block_1, & block_2,& block_3, & block_4};
arg.next = 4;
arg.x = & x;
while (1) {
if (arg.next > 4) {
return (arg.returnv);
} else {
(*(jumpTab[arg.next - 1]))(& arg);
}
}
}
These is a fifth block dispatch method which we call thread. It is essentially identical to
the call dispatch, except each call runs in its own thread. The idea is that every time
around the dispatch loop all threads are awakened, and all of them do some work, but
only one thread (the one that owns the next block to be executed) actually does any
real work. This way there is some randomness in the order in which the block functions
execute, but there is no potential for race conditions on the next variable (only one
thread will update next during each round).
This is what the code looks like for the main function that got flattened. MacOS does not support barriers, so we roll our own.
void fib(int n ) {
struct argStruct arg ;
pthread_t thrds[3];
pthread_mutex_init(&arg.mtx, NULL);
pthread_cond_init(&arg.cv, NULL);
/* Create the threads. */
pthread_create(&thrds[0], NULL, &fib_0, (void*)& arg);
pthread_create(&thrds[1], NULL, &fib_1, (void*)& arg);
pthread_create(&thrds[2], NULL, &fib_2, (void*)& arg);
arg.fib_next = 3UL; /* State machine variable. ==6 when end state reached. */
arg.fib_done = 0UL; /* How we flag the workers they should die. */
arg.n = & n;
while (1) {
/* Wake up all the threads and run one iteration of the state machine. */
pthread_mutex_lock(&arg.mtx);
arg.jobs_in_progress = ;
pthread_cond_broadcast(&arg.cv);
pthread_mutex_unlock(&arg.mtx);
pthread_mutex_lock(&arg.mtx);
while (arg.jobs_in_progress != 0) {
pthread_cond_wait(&arg.cv, &arg.mtx);
};
pthread_mutex_unlock(&arg.mtx);
/* One of the threads have set fib_next==6, this means we've
reached an end state. We're done, kill the threads. */
if (arg.fib_next == 6) {
arg.fib_done = 1;
pthread_mutex_lock(&arg.mtx);
pthread_cond_broadcast(&arg.cv);
pthread_mutex_unlock(&arg.mtx);
/* Wait for the threads to die. */
for (int i=0; i<3; i++) {
pthread_join(thrds[i], NULL);
};
pthread_mutex_destroy(&arg.mtx);
return;
}
}
}
And this is what one of the worker threads look like.
void fib_0_ (struct argStruct *arg ) {
while (1) {
/* Wait for work to arrive. */
pthread_mutex_lock(&arg->mtx);
while (!((arg->jobs_in_progress & || (arg->fib_done))) {
pthread_cond_wait(&arg->cv, &arg->mtx);
};
pthread_mutex_unlock(&arg->mtx);
/* Time to die. */
if (arg->fib_done) return;
/* Do the work assigned to us. */
switch (arg->fib_next) {
case 4: {
/* This is the end state, we're done. */
arg->fib_next = 6UL;
break;
}
case 1: {
...
}
}
/* Let the everyone know we're done. */
pthread_mutex_lock(&arg->mtx);
arg->jobs_in_progress = arg->jobs_in_progress & ~ ;
pthread_cond_broadcast(&arg->cv);
pthread_mutex_unlock(&arg->mtx);
}
}
Threaded flattening should work well with other transformations. For example, you can first virtualize your function and then flatten it with a threaded dispatch: this results in a in interpreter where each instruction handler (or piece of instruction handler) will run in its own thread. You can even flatten the same function twice, with threaded dispatch both times.
We're currently using pthreads which is unfortunate, because the calls to the
various API functions are obvious in the code (and at runtime). It would be nice to replace
these functions with some lower-level primitives.
| Option | Arguments | Description |
|---|---|---|
| --FlattenDispatch | switch, goto, indirect, call, concurrent, * | Dispatch method. Comma-separated list. Default=switch.
|
| --FlattenNumberOfThreads | INTSPEC | The number of threads created for concurrent dispatch. Default=1. |
| --FlattenSplitName | string | The name of the functions generated for call dispatch. Default=SPLIT. |
If the --FlattenConditionalKinds=flag is set, there will be no
explicit conditional tests in the code. Rather, they will be transformed
into an assembly code snippet (x86 only, at this point) that
does the comparison, extracts the flag register, and then the address to
jump to will be computed based on the individual flags set. Similar
encodings are available for Merge and Virtualize transformations.
| Option | Arguments | Description |
|---|---|---|
| --FlattenConditionalKinds | branch, compute, flag | Ways to transform conditional branches. Default=branch.
|
You can use opaque predicates and anti-implicit flow transformations to further obfuscate the next
variable.
| Option | Arguments | Description |
|---|---|---|
| --FlattenObfuscateNext | BOOLSPEC | Whether the dispatch variable should be obfuscated with opaque expressions or not. Default=false. |
| --FlattenOpaqueStructs | list, array, * | Type of opaque predicate to use. Traditionally, for this transformation, array is used. Default=array.
|
| --FlattenImplicitFlowNext | bool | Insert implicit flow between the computation of a an address and the subsequent indirect jump or call. This applies to call and indirect transformations only. Default=false. |
| --FlattenImplicitFlow | S-Expression | The type of implicit flow to insert. See --AntiTaintAnalysisImplicitFlow for a description. Default=none. |
You can virtualize a piece of a function, rather than the whole thing. Simpy put the name of the region after the function name, like this:
tigress ... --Transform=Flatten --Functions=fac:region2 ...
The region has to be defined like this in the code:
void fac(int n) {
int s=1;
int i;
for (i=2; i<=n; i++) {
TIGRESS_REGION(region2,
s *= i;
);
}
printf("fac(%i)=%i\n",n,s);
}
Note that the region needs to be ``self-contained,'' i.e. you can't jump into it, or out of it. Also, there will be some performance overhead.
comp-goto-1.c torture test:
goto *(base_addr + insn.f1.offset);
--FlattenConditionalKinds=flag transformation doesn't
work for floats, for reasons that escape me. I think maybe floats are
left on the stack and then there's a SEGV when the function returns,
but who knows? :(.
--FlattenDispatch=call --FlattenConditionalKinds=flag transformation
generates a segmentation fault, on Linux/gcc it does not. There are other similar issues that
pop up occasionally on this platform. Presumably this is due to some compiler problem related
to inline assembly. Update: I think this has been fixed now. Inline assembly with instructions
that manipulate the stack pointer can apparently be problematic.
alloca. Depending on the
platform and the size of the arrays, the generated code can crash. If so, try the option
--TransformVLA=malloc which converts VLAs to calls to malloc/free instead.
Saumya Debray and Babak Yadegari suggested the --FlattenConditionalKinds=flag transformation.