Here is an example of how to transform a function bar in a program foo.c using Tigress. The first transformation flattens the code, the second turns the flattened function into an interpreter:
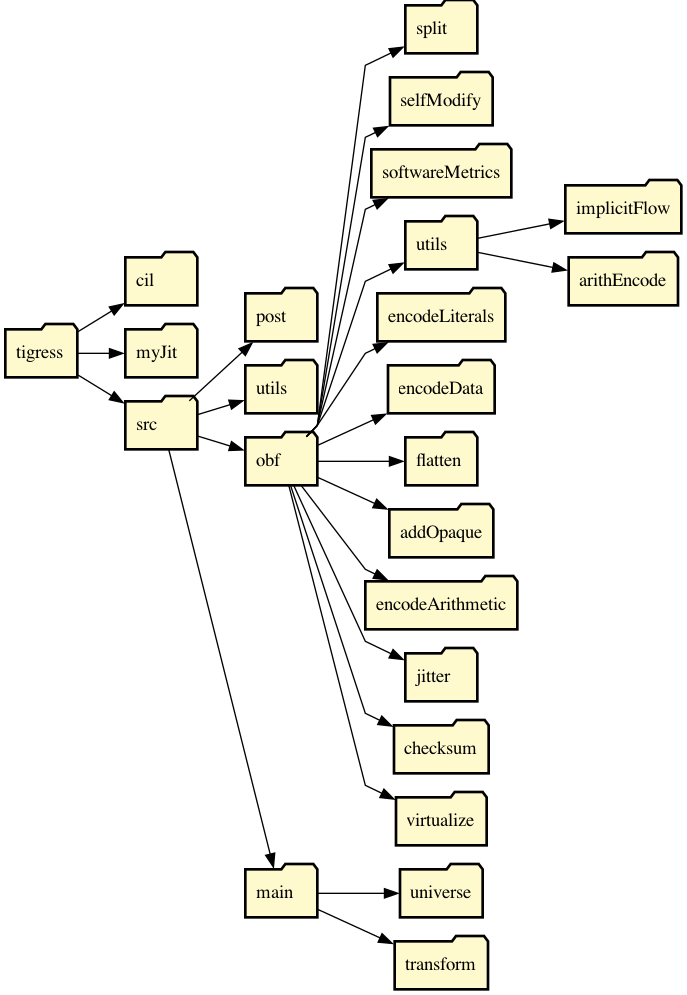
Tigress is built in OCaml (about 100,000 lines of code) and C (about 9000 lines) on top of two libraries: CIL (a C front end) and MyJit (a run-time code generator). For those who want to do Tigress development, or are merely curious of what an obfuscator looks like, I'm going to give a quick overview of the system. Here's an excerpt of the Tigress source file-tree:
The main directory is obf, which has a sub-directory for every transformation. The obf/utils directory contains libraries used by one or more transformations.
As an example, let's consider the EncodeData transformation. The infrastructure code that supports this transformation is in the directory obf/encodeData. This code is responsible for taking the input from the user (for this transformation a list of variables to be encoded), deciding which variables have to be encoded (the user may have asked for x to be encoded, but because of pointers, we may have to encode additional variables), selecting the encoding module to use, and performing the actual code transformation (such as x+y being transformed into 42^((x^42)+(y^42)) if x and y are encoded with the ValueCodecXor module).
Every transformation has to implement an interface like the one below. There are a few different variants, depending on what should be transformed. EncodeData transforms variables, so it implements the transformVariables interface:
class virtual transformVariables :
Universe.t ->
Transform.transformationKind ->
Options.t ->
object
(* Check that this transformation was called properly. *)
method functionMustNotHaveBeenPreviouslyTransformedBy :
(transformationKind * string) list
method mustHaveBeenPrecededByTransformations :
(transformationKind * string) list
method noTransformationMayFollowThisOne : string option
method notSupportedOnThesePlatforms : platform list
method deprecated : string option
(* Check for reasons this transformation can't be applied. *)
method checkTransformable : unit
(* Get variables/functions/etc that need to be transformed. *)
method private allFunctions :
Cil.fundec list
method private allReferencedFunctions :
Cil.fundec list
method private getCallers :
Cil.fundec list
method private globalTargets :
(string * string option) list
method private localTargets :
(Cil.fundec * string * string option) list
method private pseudoReturnTargets :
(string * string * string option) list
method private targetNames :
string list
method private targets :
Cil.fundec list
(* Perform the transformation. *)
method virtual transform : unit
end
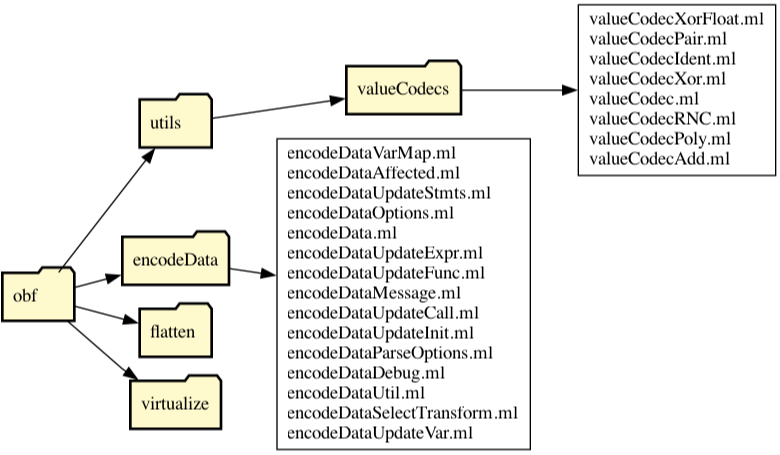
The directory obf/utils/valueCodecs holds the actual encoders. As you see, there are a number of them, since they are separated from the infrastructure component, it is easy to add new and interesting encoders. Every encoder simply has to implement the interface below, with functions that encode and decode and perform arithmetic. Note that the encode function takes an expression as input, and produced a list of expressions as output. This is to support encoders that Residue Value Numbering that splits one value into multiple values. For the same reason, binary arithmetic operates on lists of expressions:
class virtual transformer = object (self)
method virtual newTypes :
typ list
method virtual encode :
fundec -> exp -> exp list * stmt list
method virtual decode :
fundec -> exp list-> exp * stmt list
method virtual unaryOp :
fundec -> unop -> exp list -> exp list * stmt list
method virtual binaryOp :
fundec -> binop -> exp list -> exp list -> exp list * stmt list
method virtual question :
fundec -> exp -> exp list -> exp list -> exp list * stmt list
end
Most of Tigress' transformations are designed in this way: there is an infrastructure component that is in charge of performing the actual transformation, and a set of "library" units which are separate from the infrastructure, and which can easily be expanded on; opaque predicates work this way, implicit flow works this way, and so on.
Debugging a diversifying obfuscator is insanely difficult. There are many sources of complexity:
The list goes on. To make debugging relatively sane, we make extensive use of logging. You can turn it on like this:
tigress --Verbosity=3 --LogDir=log --GraphvizBuild=pdf ...
Let's look at an example, again using the EncodeData transformation. Here is the input program, encode3.c:
void ENCODE() {
int x = 41;
int* z = &x;
int** w = &z;
**w += 1;
printf("RESULT=%i\n",x);
}
int main() {
ENCODE();
return 0;
}
And here is the Tigress transformation script:
> tigress \
--LogDir=log --Verbosity=3 --GraphvizBuild=pdf \
--Environment=x86_64:Darwin:Clang:12.0 --Seed=0 \
--Transform=InitEntropy \
--Transform=EncodeData \
--EncodeDataDebug=traceUpdates \
--EncodeDataCodecs=poly1 \
--LocalVariables='ENCODE:x' \
encode3.c --out=encode3_poly1_obf.c
Notice that we've turned on logging and added additional EncodeData tracing, to help with debugging. Here's a small piece of the tracing output:
BEGIN TRANSFORM ()
STEP Alias graph after connected components have been computed:
'log/aliasGraphWithComponents_17.pdf
STEP Connected components computed from alias graph:
{0: [ENCODE:z/2987,ENCODE:x/2986, ENCODE:w/2988]}
TASK Compute affected variables.
STEP After computing affected function pointers:
target variables=[ENCODE:x/2986];
reachable variables=[];
encoded variables=[ENCODE:x/2986];
points to encoded variables= [ENCODE:
z/2987]; signature changed functions= [];
implementation changed functions= [ENCODE/2985];
init changed functions= [];
pseudo return variables=[];
components= {0: [ENCODE:z/2987,ENCODE:x/2986,ENCODE:w/2988]};
TASK Select data transformation for affected variables.
STEP Variables mapped to their encoder:
[ENCODE:x/2986->poly1:f(x:int)=1682595229*x+1015937501]
TASK Transform affected variables.
STEP Updating functions whose implementation has changed:
[ENCODE/2985]
STEP Function 'ENCODE' before variable transformations:
'ENCODE/2985' saved to log/ENCODE_25.pdf
STEP Function 'ENCODE' after variable transformations:
'ENCODE/2985' saved to log/ENCODE_27.pdf
END TRANSFORM ()
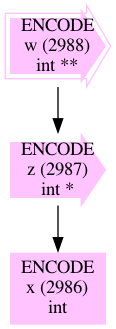
Here is the very simple alias graph that gets computed from the input program.
Here is the Abstract Syntax Tree for the input program that got produced as part of the tracing:
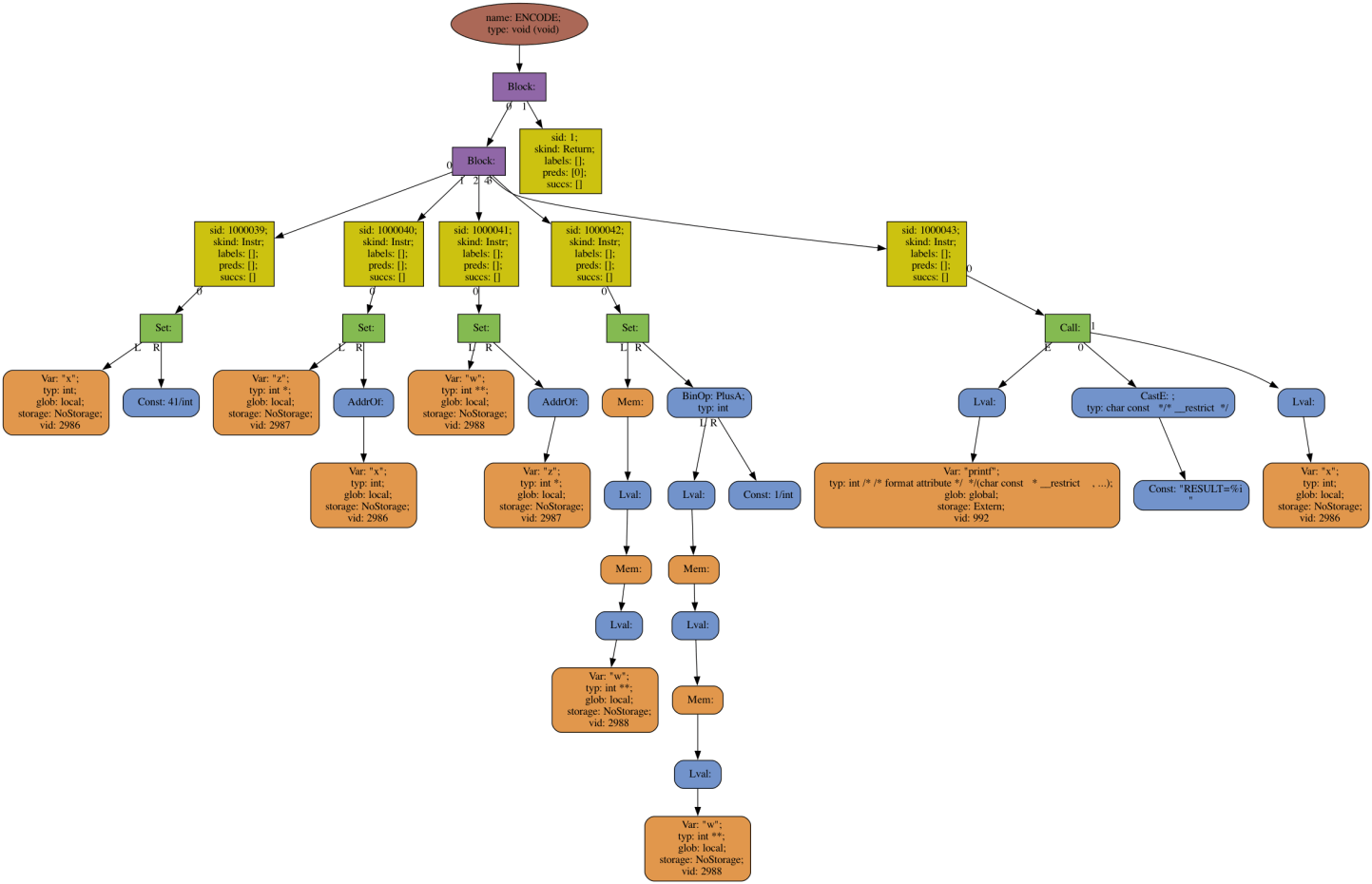
And the corresponding AST after the EncodeData transformation:
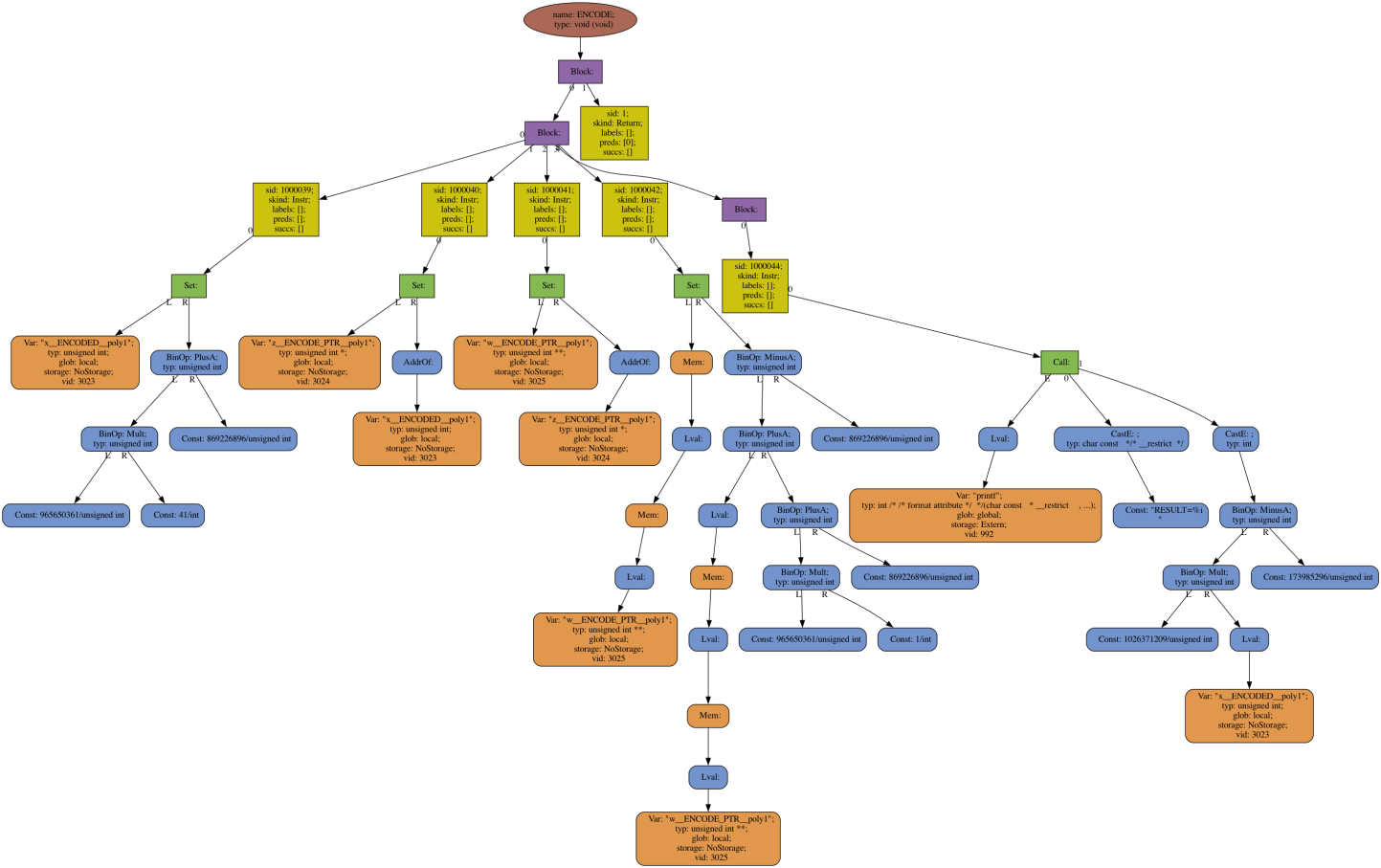
When logging is turned on, we dump the internal data structures (AST, CFG, alias graph, etc.) after each operation. When a bug is discovered, it is sometimes possible to quickly track it down by comparing subsequent data structures. If you're curious about how Tigress works internally, watching the transformation logging information can be also be very interesting.